Query Settings
Learn how to optimize query settings for Knowledge Stacks
For more accurate results, use the Query Settings to configure how your stacks should be queried during conversations.
You can setup default Query Settings from the Knowledge Stacks main configuration section.
The default Query Settings will be used when you select the corresponding stack to be used during a conversation.
From the Conversation Add-Ons, you can alter the settings for the conversation if needed.
If you select multiple stacks to be available in a conversation, then the default settings for only one of the stacks will be returned. So, it is recommended to validate and configure the query settings to be used for the conversation.
Default Query Settings
In the Knowledge Stack configuration, select Query Settings to set the defaults for that stack.
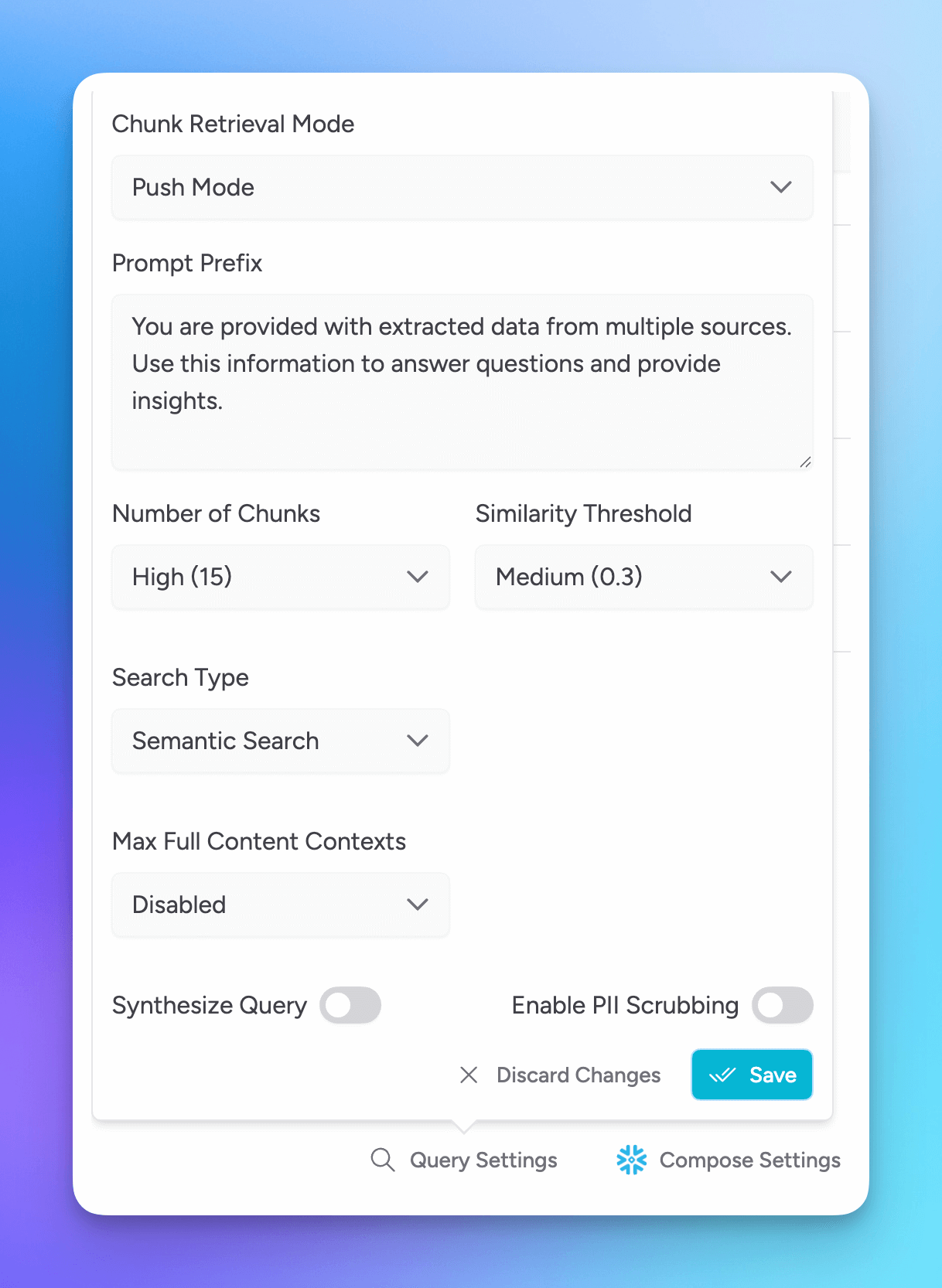
Chunk Retrieval Mode
You can set which retrieval mode is used during conversations.
Push Mode
This mode first queries the Knowledge Stack and then sends the results to the model for context.
This is the default mode.
Pull Mode
This mode first allows the model to request context from the Knowledge Stack when it identifies a need, and then retrieves the relevant results to provide to the model.
Ensure the model is able to perform tool calls if using this mode
Prompt Prefix
As with any interaction with LLMs and SLMs, it's all in the prompt.
For improved results, add a prompt that helps the model understand what they have access to and what they are expected to do with the provided context.
Number of Chunks
Set the max number of chunks that are delivered to the model.
Similarity Threshold
Define the similarity threshold. Set higher if you are looking for more exact results and similarities.
Search type
Choose how you want to search through your Knowledge Stack when retrieving relevant context.
Semantic
Semantic search uses vector embeddings to understand the meaning behind your query and retrieve conceptually similar content, even if exact words don’t match. This is ideal for natural language prompts or when you're looking for ideas, explanations, or loosely related information.
This is the default setting.
Keyword
Keyword search performs a more literal match, scanning for exact terms or phrases present in the query. This method is best for precise lookups, such as searching for specific names, terms, or technical references where wording consistency matters.
Hybrid
Hybrid search intelligently combines both semantic and keyword approaches. It allows Msty to interpret your prompt and dynamically choose the best retrieval method to maximize accuracy and relevance. Useful when you're unsure which method fits best or when queries benefit from both meaning and precision.
Max Full Content contexts Aurum Perk
By default, RAG systems retrieve and send only the most relevant chunks to the model, which is sufficient for many use cases like answering questions or extracting details. However, this approach falls short for tasks that require full-document understanding, such as summarization, narrative analysis, or comprehensive comparisons where partial context can lead to incomplete or inaccurate results.
Msty’s Knowledge Stacks supports sending the full content when needed. Use this setting to define the maximum number of full files that can be included in the model's context when such depth is required.
Note: This is disabled by default and should be used selectively based on the task and model token limits. Also, this method is triggered semantically - adjust your prompt if full context is desired but is not being provided.
Synthesize Query Aurum Perk
Synthesizing queries enables the model to generate richer, more dynamic responses by interpreting and combining relevant information from your Knowledge Stack. This leads to more context-aware interactions, especially for tasks that require reasoning, summarization, or multi-part answers.
This is disabled by default.
PII Scrubbing Aurum Perk
If you do not want personal identifiable information (PII) to be sent to the model, typically a concern when using online model providers, then enable this setting.
You will be asked to select a locally installed model that will be tasked with detecting any PII in the Knowledge Stack and to redact the information.
For best results and for added security, test PII Scrubbing in Chunks Visualizer and Chunks Console prior to using Knowledge Stacks with online providers where PII is a concern.
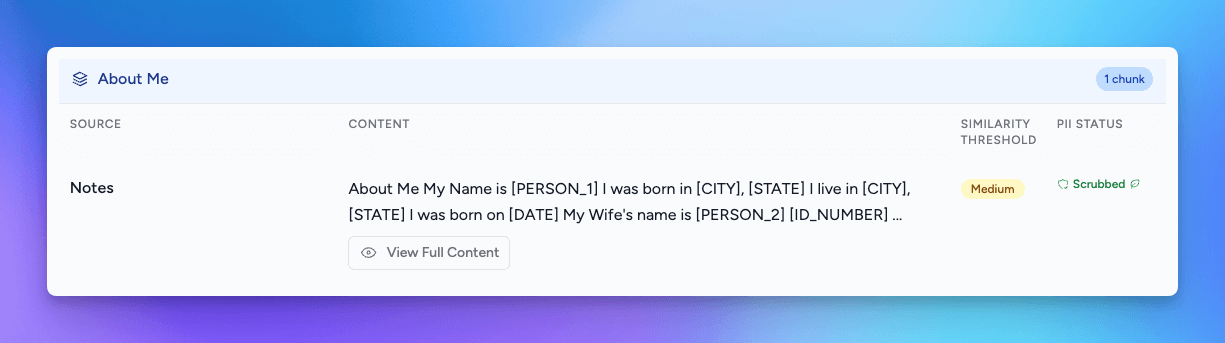
Conversation Query Settings
In conversations, the default Query Settings will be used; however, you can alter the settings for the conversation. All of the same settings are available with the exception of the prompt prefix.
If you are enabling multiple Knowledge Stacks in a conversation, be sure to review the Query Settings to ensure they are appropriate for your intended conversation.
Knowledge Stacks Query Results
In the conversation with a model, if Knowledge Stacks are enabled, you can see the results that were provided to the model.
Knowledge Stacks Metrics
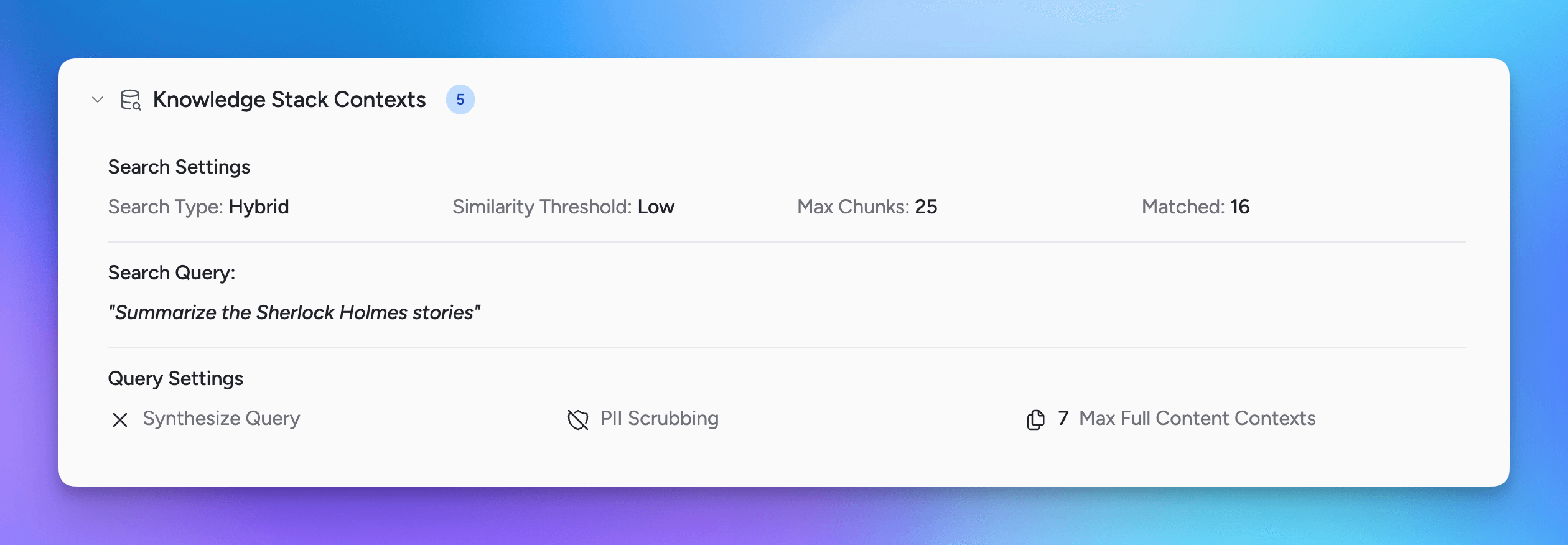
The first portion displays high level metrics for the Knowledge Stacks results as well as which settings were used to query the results with.
Query Analysis
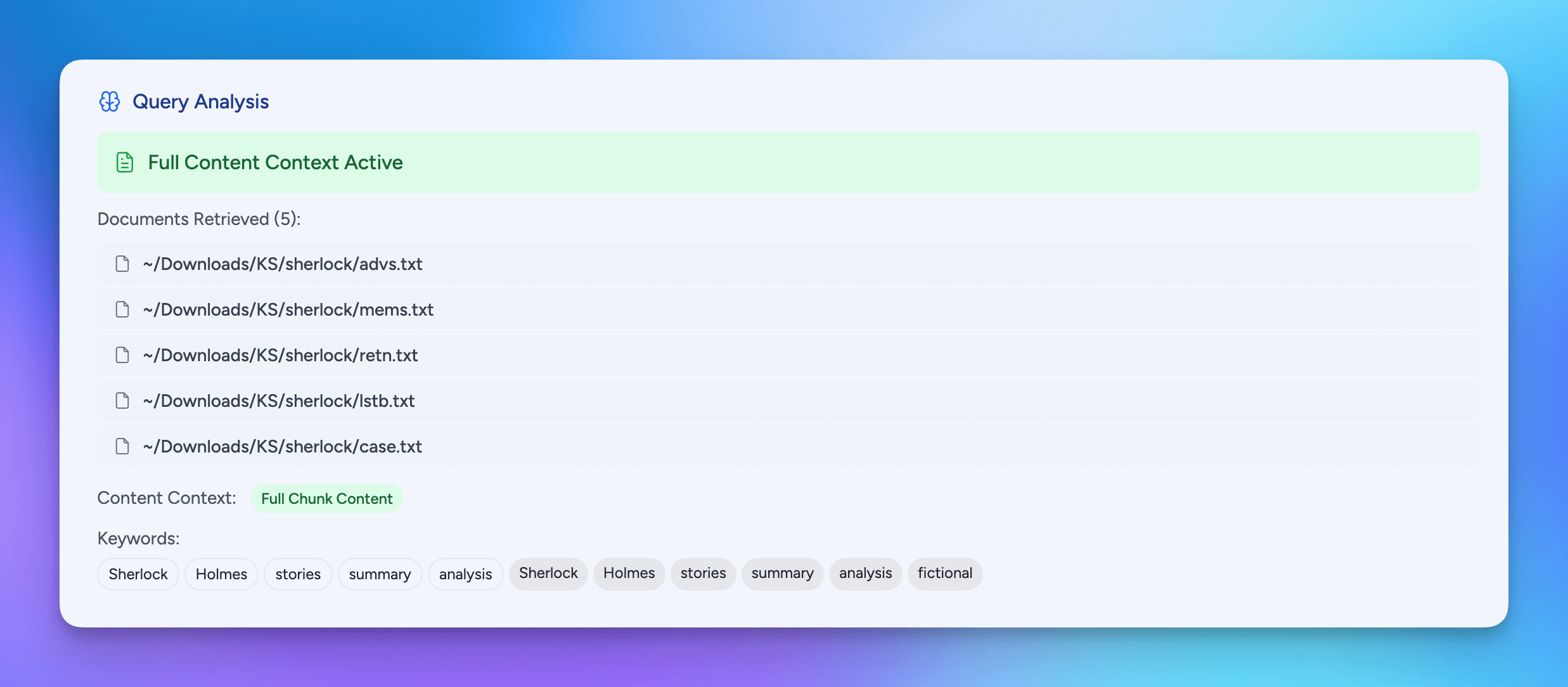 This section provides more details about which specific document resources were returned, if the contexts provided was chunks and/or full contensts, and the search keywords used and how they were weighted.
This section provides more details about which specific document resources were returned, if the contexts provided was chunks and/or full contensts, and the search keywords used and how they were weighted.
Returned Chunks and Full Contexts
 The last section shows the actual chunks and/or full contents that were returned and sent as context to the model.
The last section shows the actual chunks and/or full contents that were returned and sent as context to the model.
Related Resources
Videos


